
こんにちは。Be Free Tech、運営者の「ちきん」です。
仕事で会議が重なると、どうしても後回しになりがちなのが議事録の作成ですよね。録音した音声ファイルはあるけれど、数時間分をまた聞き直して要約するなんて、想像しただけで溜め息が出てしまいます。そんな面倒な作業を、もし「n8n」というツールで自動化できたら、もっと別のクリエイティブな仕事に時間を使えると思いませんか。
最近、巷で話題の「n8n文字起こし」に挑戦してみたのですが、これが本当にすごいんです。特にOpenAIのWhisperというAIモデルを組み合わせると、驚くほど正確に言葉を拾ってくれます。構築の過程で、APIの料金体系や有名な25MB制限など、いくつか躓きやすいポイントもありましたが、一度仕組みを作ってしまえば、あとはファイルを置くだけで勝手に議事録が出来上がるようになりますよ。
この記事では、私が実際に試行錯誤して辿り着いた、n8nを活用した文字起こし自動化の全貌を詳しく解説します。技術的な細かい設定から、運用上のコツまで、これから始めたいと考えている方の疑問を解消できる内容になっています。
- n8nとWhisperを連携させて高精度な文字起こし環境を作る手順
- 大容量ファイルの壁となる25MB制限をスマートに回避する分割テクニック
- SlackやLINE、Notionなど実用的な外部ツールとの連携パターン
- AIに議事録を要約させるための効果的なプロンプトの書き方
n8n文字起こしで実現する議事録自動化の基本
まずは、n8nを使ってどのように文字起こしの土台を築いていくかについてお話しします。自動化の仕組み作りは、一つひとつのノード(機能の塊)を繋いでいくパズルのような作業です。基本をしっかり押さえることで、後々の応用がぐっと楽になりますよ。
WhisperAPIを活用した高精度な文字起こし
私が文字起こしの自動化にハマったきっかけは、OpenAIが公開している「Whisper」というモデルの衝撃的な精度でした。これまでの音声認識ツールだと、どうしても日本語特有の言い回しや専門用語がボロボロになってしまうことが多かったんですよね。でもWhisperなら、文脈を読み取って適切な漢字に変換してくれますし、何より句読点や改行が自然に入るのが嬉しいポイントです。
n8nでこれを使うには、標準の「OpenAIノード」を利用します。このノードは設定がシンプルで、APIキーさえ用意すればすぐに使い始めることができます。私はいつも、モデル設定で「whisper-1」を選択し、言語設定(Language)には「ja」を指定するようにしています。自動判別でも動きますが、会議の冒頭が数秒間の無音だったり、雑音から始まったりすると、AIが「これは英語だ!」と勘違いして、カタカナ英語の文字起こしを生成してしまうことが稀にあるからです。最初から日本語ですよ、と教えてあげるのが安定運用のコツかなと思います。
また、Whisper APIのレスポンス形式には、単純なテキストの他にも「verbose_json」という詳細なデータ形式があります。これを使うと、各発言のタイムスタンプ(開始時間と終了時間)も取得できるので、後で動画の字幕を作りたい時などにも応用が利きます。単に文字にするだけじゃなく、その先の活用まで考えられるのが、APIならではの魅力ですね。
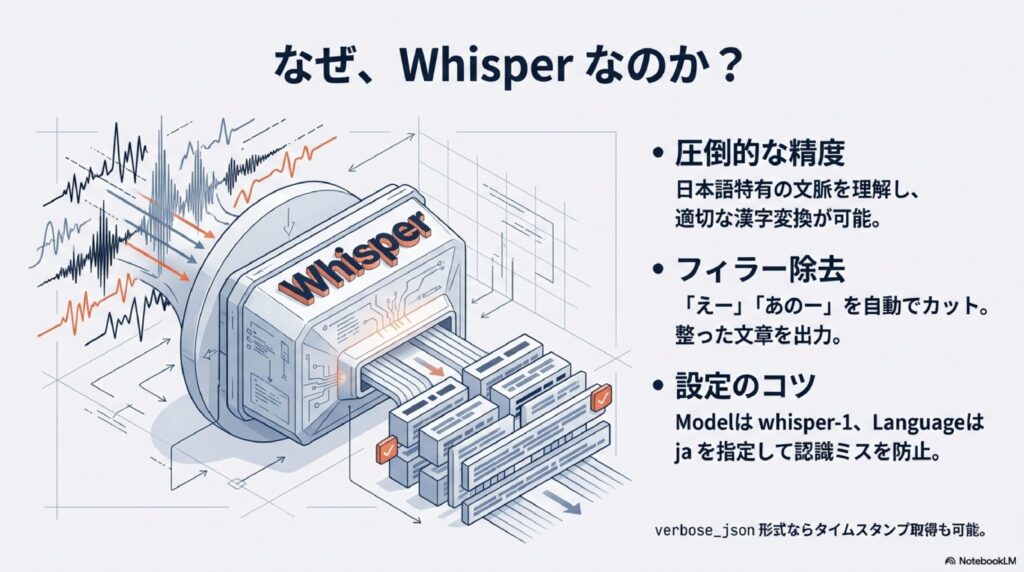
Whisper APIの最大の特徴は、「えー」「あのー」といった不要なフィラーを自動でフィルタリングして、読みやすい文章に整えてくれる点にあります。これだけで、後からの修正作業が半分以下に減ることもありますよ。
なお、Whisper APIの具体的な仕様や詳細なサポート言語については、開発元であるOpenAIの公式ドキュメントで最新情報を確認することができます(出典:OpenAI『Speech to text API Reference』)。こうした一次情報を時々チェックしておくと、新しい機能が追加された時にいち早く業務に取り入れられますね。
25MB制限を突破するファイル分割の技術
n8n文字起こしのワークフローを自作し始めると、誰もが必ず一度はぶち当たる壁があります。それが、OpenAIのAPI側で設定されている「1ファイルあたり25MBまで」という容量制限です。スマホで普通に録音したMP3ファイルだと、会議の時間が30分を超えたあたりで、あっさりとこの制限に引っかかってしまいます。せっかく順調に動いていたワークフローが「File too large」というエラーで止まってしまうのは、本当に悲しいものです。
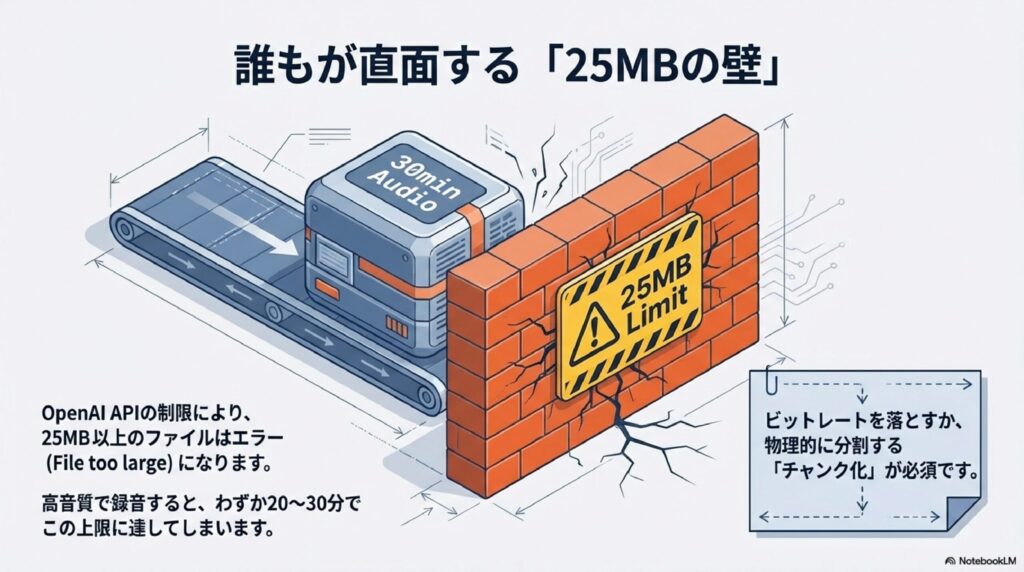
この25MBという数字、意外とシビアなんですよね。例えば、音質にこだわって高いビットレート(192kbpsなど)で録音してしまうと、20分程度で上限に達してしまいます。これを解決するためには、大きな一つの音声ファイルを、APIが受け取れるサイズまで細かく分割して、順番に(あるいは並列で)処理させる仕組みが必要です。これを「チャンク化」と呼びますが、n8nの中でこの分割ロジックを組むのが、自動化の腕の見せどころになります。
大きなファイルをそのままメモリ上で扱おうとすると、n8nを実行しているサーバーそのもののリソースを使い果たして、サービス全体がダウンしてしまうリスクもあります。大容量ファイルを処理する際は、必ず一時的なディスク書き出しを併用するようにしましょう。
具体的なアプローチとしては、後述するffmpegというツールを使って物理的に分割するか、あるいはビットレートを極限まで落として圧縮することで、同じ25MBの中でも収録時間を稼ぐという方法もあります。1時間の会議であれば、少し圧縮するだけでも25MB以下に収まることが多いですが、確実性を求めるなら「分割」の仕組みをフローに組み込んでおくのが一番かなと思います。これさえクリアできれば、数時間に及ぶ長丁場のウェビナー動画であっても、エラーを恐れずに全自動で文字起こしができるようになります。
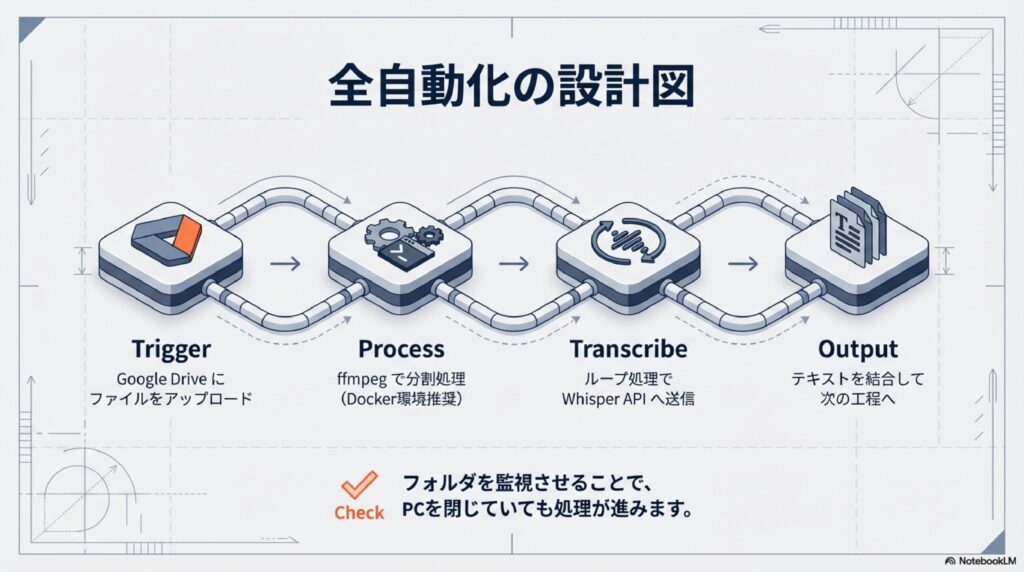
ffmpegを用いた音声データの分割処理手順
「音声ファイルを分割する」と言っても、プログラミングで一からコードを書くのは大変ですよね。そこで私が愛用しているのが、動画や音声を自由自在に操れる魔法のツール「ffmpeg」です。n8nの「Execute Command」ノードを使えば、サーバーにインストールされたffmpegに対してコマンドを送り、複雑な分割処理を一瞬で終わらせることができます。
私がよく使うのは「segment」という機能です。例えば、以下のようなコマンドをn8nから実行させます。
ffmpeg -i input.mp3 -f segment -segment_time 600 -c copy output_%03d.mp3
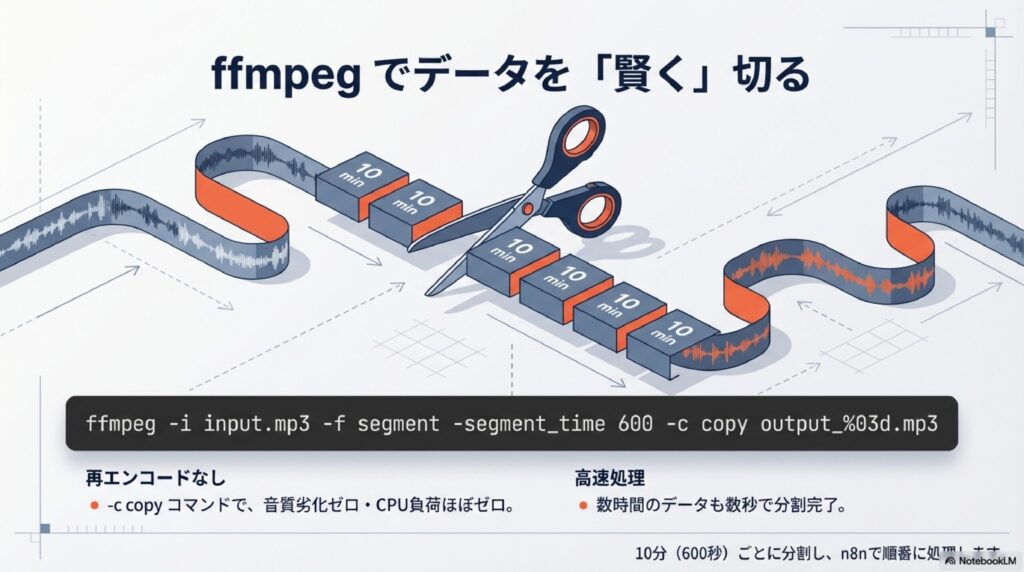
これは「元のmp3ファイルを、10分(600秒)ごとにブツ切りにする」という命令です。ここで注目してほしいのが「-c copy」という部分。これは「中身をそのままコピーする」という意味で、再エンコード(圧縮し直し)を行わないため、CPUにほとんど負荷をかけず、音質も全く劣化させずに処理が終わります。数GBあるような動画ファイルから音声だけを抜き出して分割する際も、これなら数秒で完了します。分割されたファイルは「output_001.mp3」「output_002.mp3」のように連番で保存されるので、n8nのループ機能でこれらを一つずつ読み取ってWhisperに投げていけばOKです。
ただし、一つ注意点があります。n8nをDockerなどのコンテナ環境で動かしている場合、標準のイメージにはffmpegが含まれていないことがあります。その場合は、Dockerfileを少し編集してffmpegをインストールしたカスタムイメージを作る必要があります。最初は少し手間かもしれませんが、一度環境を整えてしまえば、あらゆるメディア処理の自動化に応用できる最強の武器になりますよ。
ffmpeg活用のメリット
- 処理速度が極めて速く、サーバー負荷を抑えられる
- 音質の劣化がなく、AIの認識精度を維持できる
- 無音部分の自動カットなど、高度な前処理も可能
GoogleDriveとの連携でファイルを自動取得
文字起こしの自動化を完成させる最後のピースは、「どこから音声を持ってくるか」という入り口の部分です。私はこれまで色々なパターンを試しましたが、最終的に一番使い勝手が良かったのがGoogle Driveとの連携でした。Google Driveの特定のフォルダを「監視対象」にしておき、そこにファイルが入った瞬間にn8nのワークフローが動き出す仕組みです。
n8nには「Google Drive Trigger」という専用のノードが用意されていて、これを使えばプログラミングなしで簡単にフォルダの監視設定ができます。例えば、「議事録作成中」というフォルダを作っておき、録音したデータをスマホのドライブアプリからそこにアップロードするだけ。あとはパソコンを閉じていても、n8nが勝手にファイルを見つけ、ffmpegで分割し、Whisperで文字にし、要約まで終わらせてくれます。この「放っておいても進む」という感覚が、自動化の醍醐味ですね。
実際の設定では、トリガーノードの後に「Google Driveノード」を繋いで、ファイルのバイナリデータ(中身)をダウンロードするステップを入れます。この時、n8nが一度に扱えるデータ量には上限がある場合が多いので、特に大容量のファイルを扱う時は、前述のように一度ローカルのテンポラリフォルダに保存してから処理を進めるのが安全です。設定画面で「Property Name」に指定した名前が、次のノードに渡されるデータの名前になるので、そこを間違えないように注意してくださいね。
Google Drive以外にも、OneDriveやDropbox、あるいは自社サーバーのSFTPフォルダなども監視対象にできます。チームで共有しているフォルダを使えば、メンバーの誰かが録音を置くだけで全員に議事録が共有される、なんて素敵な運用も可能ですよ。
初心者でも分かるn8nの基本的な使い方
ここまで少しテクニカルなお話もしてきましたが、そもそもn8nを初めて触るという方に向けて、画面の見方や基本的な考え方もおさらいしておきますね。n8nは「ワークフロー・オートメーション」と呼ばれるツールで、最大の特徴は「全てを視覚的に繋いで管理できる」ことです。画面上に機能ごとのブロック(ノード)を置いて、それらを線で結ぶことでデータの流れを作っていきます。
最初は「どう繋げばいいのか分からない!」と戸惑うかもしれませんが、基本は「左から右へ」です。
- 「Trigger」:何かが起きた時にワークフローをスタートさせる(例:時間が来た、ファイルが置かれた)
- 「Action」:何かを処理する(例:ファイルをダウンロードする、AIに送る)
- 「Filter / Branch」:条件によって分ける(例:ファイルがmp3だったら進む、それ以外なら止める)
文字起こしフローなら、この3つの組み合わせだけで完成します。n8nの良いところは、各ノードをクリックすると「今どんなデータがここを通っているか」をリアルタイムで見られる点です。エラーが起きた時も、どこの線が繋がっていないのか、どのノードで止まったのかが一目でわかるので、初心者の方でもトラブル解決が比較的しやすいかなと思います。
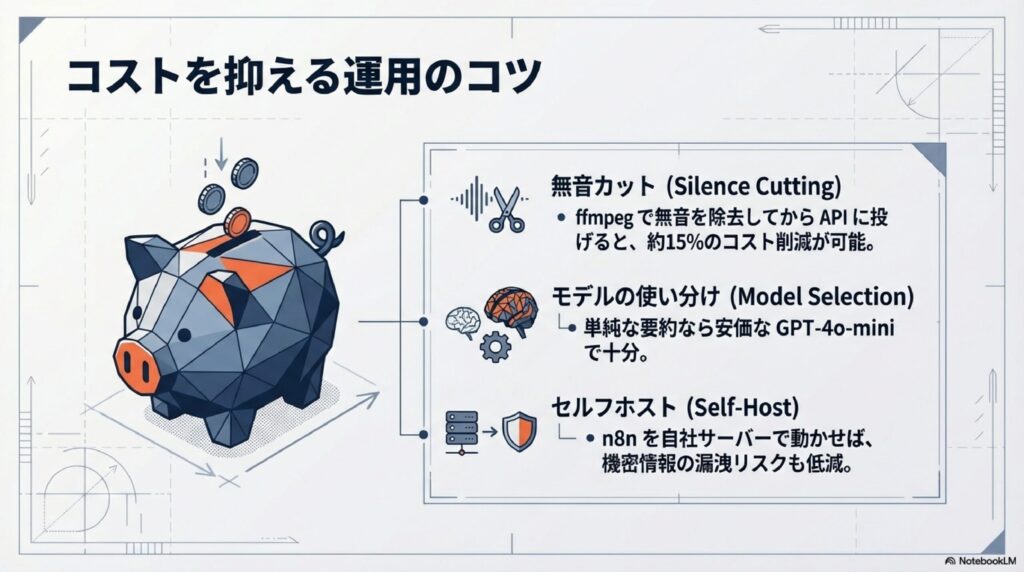
また、n8nは「セルフホスト(自分のサーバーで動かす)」ができるのも大きな魅力です。音声データは機密情報を含むことが多いので、クラウドサービスに預けるのが不安な場合でも、自分の管理下のサーバーでn8nを動かせば、データを外部に漏らさずに自動化の恩恵を受けられます。自由度が高すぎて最初は迷うかもしれませんが、まずは「1つの音声ファイルを1つのテキストにする」という極小のフローから始めてみるのが、一番の近道ですよ。
n8n文字起こしとAIを連携した議事録作成
文字起こししただけのテキストは、実はまだ「素材」の状態です。ここからは、その素材をさらに美味しく調理して、ビジネスで即戦力になる「議事録」に変えていくプロセスについて深掘りしていきます。AIの力を借りれば、人間以上のスピードで完璧なまとめが作れます。
ChatGPTで議事録を自動要約するプロンプト
Whisperで作った文字起こし結果をそのまま読むと、意外と読みにくいことに気づくはずです。話し言葉には「えーと」のような不要な言葉だけでなく、同じことを何度も繰り返したり、主語が抜けていたりと、情報の密度が低い部分が多いからです。そこで登場するのがChatGPT(GPT-4oなど)の要約能力です。文字起こし結果を「OpenAI Chat Model」ノードに渡して、内容を整理させます。
ここで一番重要なのが「プロンプト(指示出し)」です。単に「要約して」と送るだけでは、せっかくの重要な詳細が削ぎ落とされて、味気ない数行の文章になってしまうことがよくあります。私が工夫しているのは、AIに「プロフェッショナルな書記」としての役割を与えた上で、出力形式を厳密に指定することです。具体的には、「決定事項」「議論の背景」「宿題(アクションアイテム)」といった見出しを作らせて、誰が・いつまでに・何をやるのかを明確に抽出させます。
また、長時間の会議で文字起こしが膨大になった場合は、一度にAIへ送ると制限(コンテキストウィンドウ)に引っかかることがあります。そんな時は、n8nの中でテキストをいくつかに分割して個別に要約させ、最後にそれらを結合して「全体のまとめ」を作るという、いわゆる「マップリデュース(Map-Reduce)」の手法を使うと、精度が劇的に上がります。少し複雑なフローになりますが、これをやるだけで議事録のクオリティが別次元になりますよ。

プロンプトに「箇条書きで出力してください」「専門用語はそのまま維持してください」という一文を添えるだけで、ビジネスシーンでそのまま使える綺麗なフォーマットが手に入ります。
作成した議事録をSlackへ即座に通知する
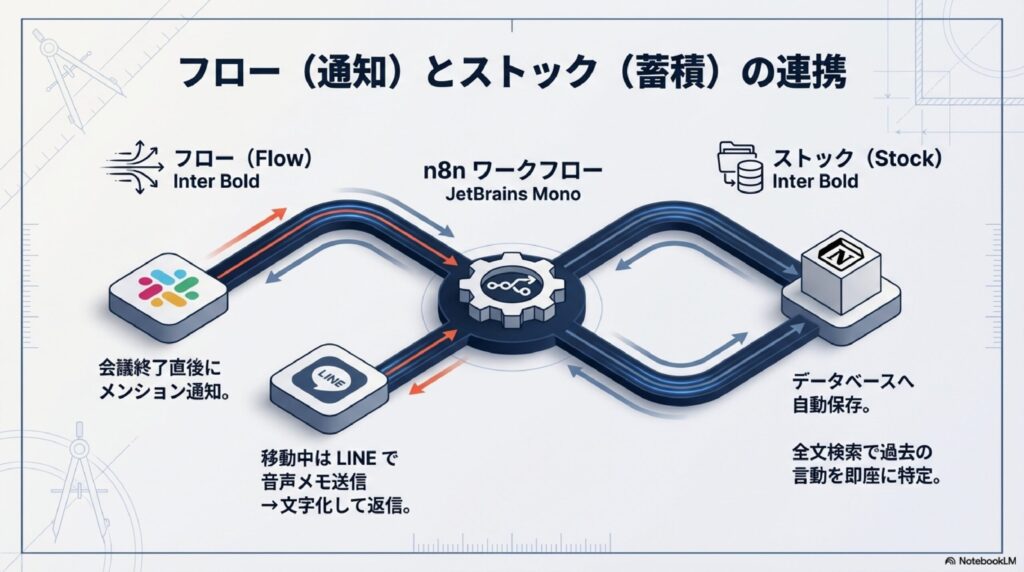
どんなに素晴らしい議事録が出来上がっても、それを自分だけが持っていたのでは意味がありませんよね。情報の価値は共有されることで最大化します。n8nなら、AIが要約を書き終えた瞬間、自動的にチームのSlackチャンネルへメッセージを飛ばす設定が可能です。これがまた、メンバーからの評判がすごく良いんです。
n8nの「Slackノード」を使って設定を行います。単にテキストを貼り付けるだけでなく、Slackの装飾(Markdown)を活かして、決定事項を太字にしたり、セクションごとに区切り線を引いたりすると、スマホからパッと見た時でも内容が頭に入ってきやすくなります。また、元の長文テキストへのリンクを添えておけば、「要約だけじゃなくて詳細も知りたい」というメンバーのニーズにも応えられますね。
個人的には、会議の参加者全員に自動でメンションを飛ばす設定も気に入っています。会議が終わってから10分も経たないうちに、「今日のまとめはこちらです!」とSlackに通知が来る。このスピード感は、一度体験するともう手放せません。議事録担当者が数日かけてまとめるのを待つ必要がなくなり、チーム全体の動きが明らかに軽くなるのを実感できるはずです。n8nを使えば、Slack以外のChatworkやMicrosoft Teamsへの通知も同じように組めますよ。
LINE連携で外出先から音声送信と確認
「会議」だけが文字起こしの舞台ではありません。私は外出中や移動中にふと思いついたアイデアを忘れないように、LINEを使った音声メモの自動化も活用しています。これが驚くほど便利で、歩きながらスマホに話しかけるだけで、数分後には整理されたテキストが手元に届くんです。
仕組みはこうです。まずLINEの公式アカウント(自分専用)を作成し、そのWebhookをn8nの「LINE Trigger」で受け取ります。音声を送信すると、n8nがその音声データを取得してWhisperに回し、その結果をまたLINEで自分宛に返信させます。これなら立ち止まってフリック入力する必要もなく、思考のスピードでメモを残せます。さらに、そのメモの内容が「タスク」だとAIが判断した場合は、自動的にToDoリストに追加する、なんていう高度な連携もn8nなら自由自在です。
LINEでの音声送信は非常に手軽ですが、マイクとの距離や周囲の騒音には注意してください。ノイズキャンセリングが効いたイヤホンマイクを使うと、さらに認識精度がアップしますよ。
このLINE連携は、キーボードを打つのが難しい状況(例えば荷物を持っている時や料理中など)でも情報をアウトプットできるため、QOL(生活の質)の向上にも直結するなと感じています。プライベートの備忘録から、仕事のクイックな報告まで、活用の幅は無限大ですね。
導入コストを抑えるAPI料金の節約術
自動化を運用する上で、どうしても避けて通れないのが「お金」の話です。n8n自体はセルフホストすれば基本無料(あるいはサーバー代のみ)ですが、Whisper APIやChatGPTのAPIは使った分だけ料金が発生します。便利なのは分かっているけれど、コストが膨れ上がるのは怖い……という不安、私も最初はありました。
現在の一般的な目安として、APIの料金体系を整理してみました。以下の表は、頻繁に利用されるモデルのコスト感をまとめたものです。
| サービス名/モデル | コストの目安(2026年時点) | 主な用途 | 節約のポイント |
|---|---|---|---|
| Whisper API (whisper-1) | $0.006 / 1分あたり | 音声のテキスト化 | 無音区間を削除して送信時間を短縮する |
| GPT-4o (Chat API) | 入力/出力トークンごとの従量課金 | 高度な要約・構造化 | 要約には安価な「GPT-4o-mini」を活用する |
| n8n セルフホスト | サーバー費用 (月額500円〜) | 全体の制御・ハブ | 不要な実行ログを定期的に削除してディスクを節約 |
コストを抑える最大のコツは、「AIに渡す前にデータを整える」ことです。例えば、1時間の音声の中に合計10分の沈黙があるなら、ffmpegを使って無音部分を自動でカットしてからWhisperに送りましょう。それだけで、APIの課金対象時間が10分減り、料金も15%以上カットできます。また、日常的なメモの要約などは、最新の最強モデルを使わなくても、軽量版のモデル(GPT-4o-miniなど)で十分事足りることが多いです。用途に合わせて道具を使い分けるのが、賢い自動化運用のポイントかなと思います。
Notionに議事録を保存し自動化を完結する
さて、最後の仕上げは情報の「ストック」です。Slackへの通知は便利ですが、情報はどんどん流れていってしまいます。数ヶ月後に「あの件、どう決まったんだっけ?」と振り返るためには、構造化されたデータベースに蓄積しておくのが一番です。私はここでNotionを愛用しています。
n8nの「Notionノード」を使うと、文字起こしが完了したタイミングでNotionのデータベースに新しいページを自動作成できます。ページタイトルには会議の日付と議題を入れ、プロパティにはAIが生成した要約、さらにはオリジナルの音声ファイルへのリンクなどを整理して格納します。ページの中身(コンテンツ)には、全文の文字起こしテキストを流し込んでおけば、Notionの強力な検索機能を使って、過去の全会議の中から特定の単語を探し出すことも可能になります。
この「情報のフロー(Slack)とストック(Notion)」を同時に自動で行えるのが、n8nを使う最大のメリットかもしれません。人間がいちいちコピペして整理する必要はありません。一度設定してしまえば、あなたはただ会議に出て、終わったら録音を置くだけ。それだけで、チーム共有用の速報と、組織の資産としての議事録データベースが同時に更新される……そんな魔法のような環境が手に入ります。情報の整理整頓に追われる日々から卒業して、もっと大切な決断のために頭を使っていきましょう。
n8n文字起こしの相談はプロにお任せ
ここまで、n8n文字起こしの魅力と具体的な構築方法についてお話ししてきましたが、いかがでしたでしょうか。「意外とできそう!」と思った方もいれば、「設定が多すぎて難しそう……」と感じた方もいらっしゃるかもしれません。確かに、APIの連携エラーやサーバー側の設定、25MB制限の突破ロジックなど、スムーズに動かすまでにはいくつかのハードルがあるのは事実です。
もし、「自分の業務に合わせた独自のワークフローを作ってほしい」「設定で詰まっているところを助けてほしい」というお悩みがあれば、ぜひ私にご相談ください。Be Free Techでは、n8nをはじめとした自動化ツールの導入支援を行っています。

あなたの会社の現在のワークフローをヒアリングし、Google DriveやSlack、Notion、そしてAIを最適に組み合わせた、世界に一つだけの自動化システムを構築いたします。面倒な初期設定や複雑なデバッグは私が引き受けますので、皆さんは完成した便利なシステムを使って、業務の効率化をすぐに実感していただけます。
最後になりますが、今回ご紹介したAPIの料金やモデルの性能などは、あくまで執筆時点の一般的な情報です。AIの世界は日進月歩ですので、導入の際は必ず各サービスの公式サイトで最新の利用規約やプライバシーポリシーを確認してくださいね。また、機密性の高い音声データを扱う際は、情報漏洩のリスクを十分に考慮したセキュリティ設定が不可欠です。不安な場合は、専門家のアドバイスを受けることも一つの手です。
n8n文字起こしは、単なる時短ツールではなく、仕事のスタイルそのものを変えてくれる大きな可能性を秘めています。この記事が、あなたの新しい挑戦の一助になれば幸いです。それでは、また次回の記事でお会いしましょう!
Be Free Techでは、他にも業務自動化に役立つ情報を発信しています。n8nの基本的なインストール方法や、ChatGPTをさらに使いこなすコツなども紹介しているので、ぜひ他の記事も覗いてみてくださいね。
「まずは気軽に相談したい」という方へ
制作のご依頼やシステム構築に関するご相談、また副業に関するお悩みは、NEW公式LINEでも受け付けております。メールフォームよりも迅速なレスポンスが可能です。


